Agistra — Why I Gave My AI Team Roles Instead of a Better Prompt
Why a single LLM in a loop breaks down past toy projects, and what changed when I split the work across four agents with explicit handoff contracts.
Every session used to start the same way: re-explain the stack, re-explain what I’d already decided, re-explain what broke last time. Fifteen minutes of context-loading before any real work happened. Do that twice a day for a few months and you start resenting the tool that’s supposed to save you time.
The fix wasn’t a better prompt. It was admitting that one model playing every role — architect, builder, QA, project manager — doesn’t scale past a toy project, for the same reason it doesn’t work with humans.
What was actually breaking
Not tokens, not speed. Four specific failure modes, all of them familiar if you’ve run AI-assisted dev for more than a few weeks:
- Decisions didn’t survive sessions. I’d work through an approach, rule out two alternatives, settle on a pattern — and the next session would just guess again, often guessing wrong, and I’d find the bad call after it was already wired in.
- Architecture drift. Ask for one feature, receive that feature plus an uninvited refactor in a different style than the rest of the codebase.
- No real handoff. The same agent that wrote the code declared it tested. It tested what it already believed worked, not what the spec actually required.
- I was the project manager. Task state, priorities, what’s actually done versus what was claimed done — all of it lived in my head, reloaded from scratch every morning.
None of these are prompting problems. They’re structure problems.
Four agents, not one
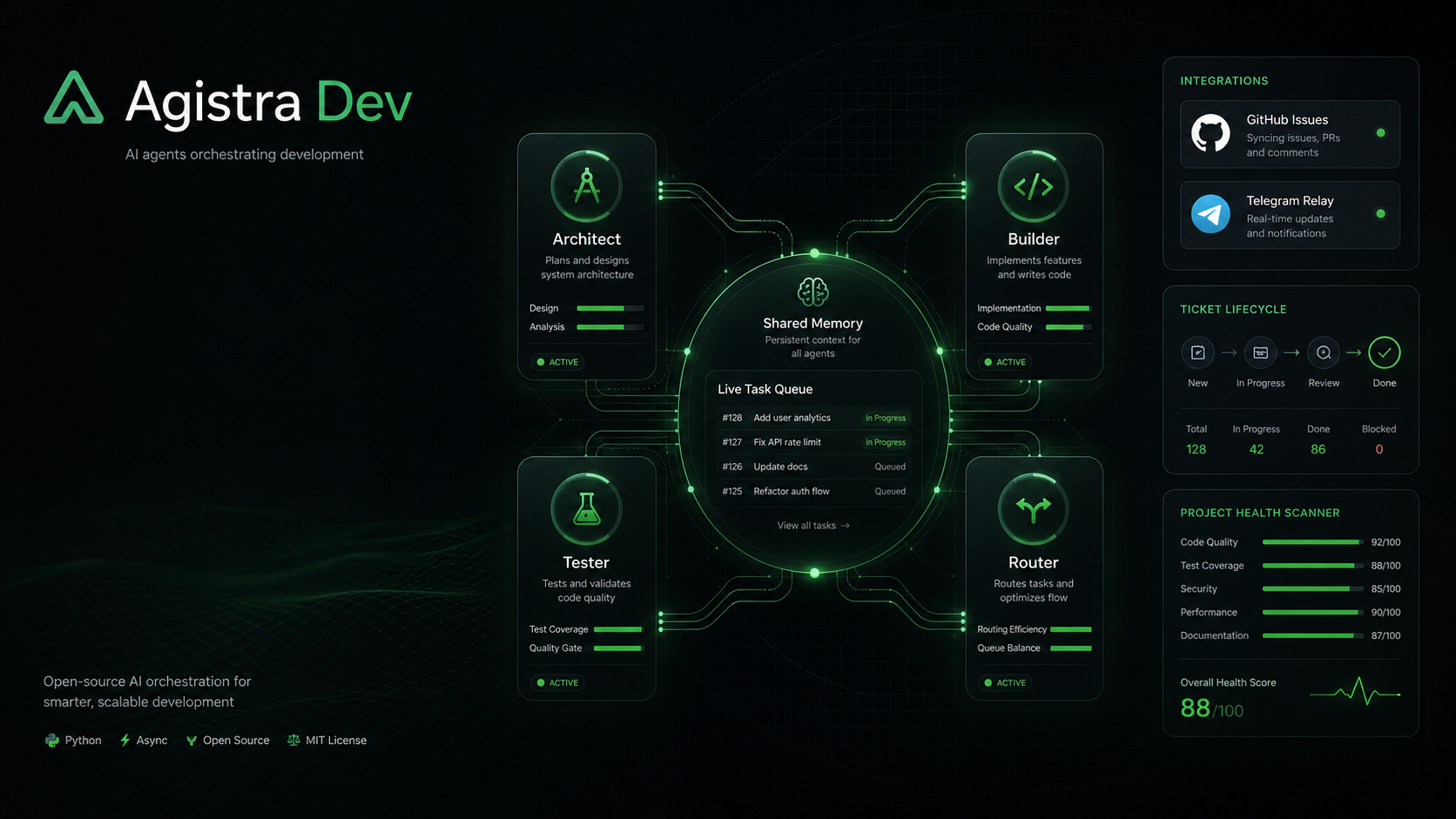
Agistra splits the work into roles with real boundaries, not just labeled personas:
- Architect — scopes work, writes ADRs, generates tickets. Doesn’t implement.
- Builder — implements only what the ticket specifies. Can’t create tickets, can’t expand scope, can’t decide the ticket was wrong.
- Tester — black-box QA against the running app. Never reads implementation intent, never reads the diff — only the spec and the behavior.
- Router — relay and message classification between this hub and any remote team.
Each one runs in its own workspace with its own identity and its own memory file. They don’t talk to each other directly. Everything routes through the ticket queue, which is just markdown files in git — no message broker, no database, nothing that breaks when a process restarts.
The part that actually mattered: handoff contracts
Splitting roles is easy. Making the splits hold under pressure is the hard part, and that came down to a few rules I had to enforce explicitly, because the model won’t enforce them on its own:
A ticket needs testable acceptance criteria and a named verifier before Builder touches it. Underscoped work gets returned, not guessed through. “Make the nav better” is not a ticket.
Three consecutive test failures parks the ticket. No infinite retry loop where the model keeps patching its own patch. Escalate and move on.
Builder can’t declare QA done. That gate belongs to Tester, full stop, because the agent that wrote the code is structurally the worst-positioned judge of whether it actually works.
Model routing is a runtime decision, not a config flag. Simple tickets run on Haiku. Multi-file work or anything involving debugging runs on Sonnet. Picking the cheap model for a hard problem doesn’t save money — it just produces a worse result you pay to fix twice.
Memory across restarts
Each agent keeps a HOT / WARM / COLD memory file, updated at the start and end of every session — HOT for what’s active right now, WARM for recent decisions worth surfacing, COLD for stable patterns that don’t need re-litigating. A cold restart becomes a warm pickup instead of a blank page. Compaction is something the system handles on purpose, not an edge case I discover the hard way mid-task.
There’s also a health scanner that scores a project across five perspectives — system structure, test coverage, README/doc quality, CI/CD automation, and debug hygiene (stray TODOs, leftover console.logs) — and writes the trend to disk after every scan. The point isn’t the score. It’s that nobody was watching test coverage quietly drop until it was already a problem, and now something is.
What I’d tell someone copying this
Don’t start with four agents. Start with the one rule that’s actually costing you time — usually it’s either “the same agent writes and grades its own work” or “nothing survives between sessions” — and fix that first. The role separation matters less than the contracts between roles. A clean four-agent system with no handoff rules degrades into the same single-LLM mess, just with extra ceremony.
Agistra is open source: github.com/vsetchinfc/agistra.dev. The docs for each agent role (docs/ARCHITECT.md, docs/BUILDER.md, docs/TESTER.md, docs/ROUTER.md) are the actual lifecycle rules I run on, not a simplified version for public consumption.